大數(shù)據(jù)處理已成為當(dāng)今信息時代的核心技術(shù)之一,它依賴于海量數(shù)據(jù)的收集、存儲、分析和應(yīng)用。在了解大數(shù)據(jù)處理的具體流程之前,我們需要先明確這些數(shù)據(jù)從何而來,然后再探討如何進(jìn)行高效處理。
一、大數(shù)據(jù)的數(shù)據(jù)來源
大數(shù)據(jù)的來源極其廣泛,主要可以分為以下幾個方面:
- 互聯(lián)網(wǎng)與社交媒體:用戶在網(wǎng)絡(luò)上的行為數(shù)據(jù),如瀏覽歷史、搜索記錄、社交媒體互動(點贊、評論、分享)、在線購物記錄等,構(gòu)成了大數(shù)據(jù)的重要部分。例如,電商平臺通過收集用戶的購買和瀏覽數(shù)據(jù),進(jìn)行個性化推薦。
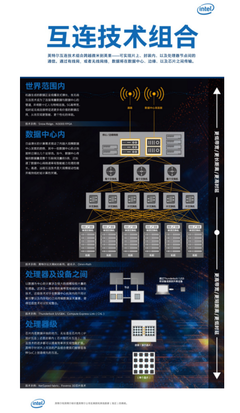
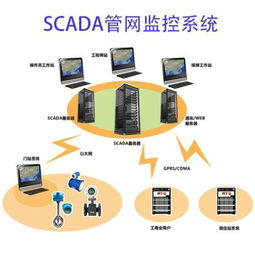
- 物聯(lián)網(wǎng)設(shè)備:隨著物聯(lián)網(wǎng)技術(shù)的普及,各種智能設(shè)備(如傳感器、攝像頭、智能家居設(shè)備)持續(xù)生成大量數(shù)據(jù)。例如,工業(yè)傳感器采集的溫度、濕度和壓力數(shù)據(jù),可用于預(yù)測設(shè)備故障。
- 企業(yè)運營數(shù)據(jù):企業(yè)內(nèi)部系統(tǒng)(如ERP、CRM、財務(wù)系統(tǒng))產(chǎn)生的數(shù)據(jù),包括交易記錄、客戶信息、生產(chǎn)日志等。這些數(shù)據(jù)有助于企業(yè)優(yōu)化運營和決策。
- 公共數(shù)據(jù)源:政府機構(gòu)、科研機構(gòu)和開放數(shù)據(jù)平臺提供的數(shù)據(jù),如人口普查數(shù)據(jù)、氣象數(shù)據(jù)、交通流量數(shù)據(jù)等。這些數(shù)據(jù)常用于公共政策分析和城市規(guī)劃。
- 移動設(shè)備與位置數(shù)據(jù):智能手機、GPS設(shè)備生成的位置信息、應(yīng)用使用數(shù)據(jù)等,可用于分析用戶行為模式和交通狀況。
這些數(shù)據(jù)通常具有量大、速度快、類型多的特點(即4V特性:Volume、Velocity、Variety、Veracity),為大數(shù)據(jù)處理提供了豐富的基礎(chǔ)。
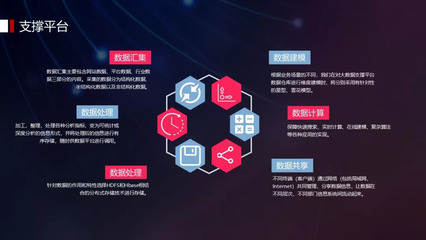
二、大數(shù)據(jù)處理的關(guān)鍵流程
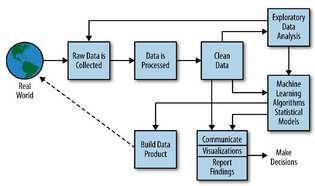
數(shù)據(jù)收集后,需要經(jīng)過一系列處理步驟才能轉(zhuǎn)化為有價值的信息。大數(shù)據(jù)處理主要包括以下環(huán)節(jié):
- 數(shù)據(jù)采集:通過API、爬蟲、傳感器接口等方式,從各種來源收集原始數(shù)據(jù)。這一步需確保數(shù)據(jù)的完整性和實時性。
- 數(shù)據(jù)存儲:由于數(shù)據(jù)量巨大,傳統(tǒng)數(shù)據(jù)庫難以應(yīng)對,因此常用分布式存儲系統(tǒng)(如Hadoop HDFS、NoSQL數(shù)據(jù)庫)來存儲數(shù)據(jù)。
- 數(shù)據(jù)清洗與預(yù)處理:原始數(shù)據(jù)常包含噪聲、缺失值或錯誤信息,需進(jìn)行清洗、去重、格式轉(zhuǎn)換等操作,以提高數(shù)據(jù)質(zhì)量。
- 數(shù)據(jù)分析與挖掘:使用機器學(xué)習(xí)、統(tǒng)計模型或數(shù)據(jù)挖掘技術(shù),從數(shù)據(jù)中提取模式和洞見。例如,聚類分析可用于客戶細(xì)分,預(yù)測模型可預(yù)測未來趨勢。
- 數(shù)據(jù)可視化與應(yīng)用:將分析結(jié)果以圖表、儀表盤等形式呈現(xiàn),幫助用戶理解數(shù)據(jù),并應(yīng)用于業(yè)務(wù)決策、產(chǎn)品優(yōu)化等領(lǐng)域。
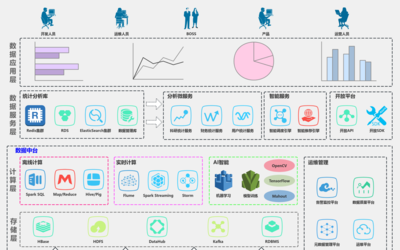
整個過程可能涉及多種技術(shù)工具,如Apache Spark用于實時數(shù)據(jù)處理,Hadoop用于批處理,以及Python、R等編程語言進(jìn)行數(shù)據(jù)建模。
大數(shù)據(jù)的來源多樣且不斷擴展,其處理流程需要綜合運用多種技術(shù)手段。隨著人工智能和云計算的發(fā)展,大數(shù)據(jù)處理正變得更加高效和智能化,為各行各業(yè)帶來了巨大價值。